
Mastering DataFrame Joins in Spark: A Comprehensive Guide with Examples
Discover the essential guide to mastering DataFrame joins in Spark with runnable examples. Learn different types of joins and how to implement them for effective data transformation and analysis.

Introduction
DataFrames are a core component of Apache Spark, designed for large-scale data processing. They offer a versatile and efficient way to handle big data, making them essential for data scientists and engineers. One of the most powerful features of DataFrames is the ability to join different datasets, enabling complex data transformations and analyses. This blog aims to provide a clear understanding of DataFrame joins in Spark, complete with runnable examples to help you get hands-on experience.
What is a DataFrame?
A DataFrame in Apache Spark is a distributed collection of data organized into named columns, similar to a table in a relational database. Unlike traditional RDBMS tables, Spark DataFrames can handle large volumes of data across a distributed environment, leveraging Spark's optimized execution plans and in-memory processing capabilities.
Benefits of Using DataFrames in Big Data Processing:
Distributed Computing: DataFrames can process large datasets across multiple nodes in a cluster.
Optimized Execution Plans: Spark's Catalyst optimizer improves query performance.
Ease of Use: High-level APIs in multiple languages (Scala, Python, R, and Java).
Types of Joins in Spark
Spark offers several types of joins to cater to different data integration needs:
Inner Join: Returns only the rows that have matching keys in both DataFrames.
Left Join: Returns all rows from the left DataFrame and matched rows from the right DataFrame. Unmatched rows from the left DataFrame will have null values for columns from the right DataFrame.
Right Join: Similar to left join but returns all rows from the right DataFrame.
Full Outer Join: Returns all rows when there is a match in either the left or right DataFrame. Rows without matches in the other DataFrame will have null values.
Cross Join: Returns the Cartesian product of the two DataFrames.
Semi Join: Returns only the rows from the left DataFrame that have matching rows in the right DataFrame.
Anti Join: Returns only the rows from the left DataFrame that do not have matching rows in the right DataFrame.
Setting Up Spark Environment
To work with Spark locally, follow these steps:
Installation of Apache Spark:
Download Apache Spark from the official Spark website.
Extract the downloaded file and set the
SPARK_HOMEenvironment variable.
Setting Up Local Compiler: For Python users, install PySpark:
pip install pyspark
Initializing a Spark Session:
from pyspark.sql import SparkSession
spark = SparkSession.builder \\
.appName("DataFrame Joins") \\
.getOrCreate()
DataFrame Creation
Creating DataFrames in Spark is straightforward. Let's start with a sample dataset for demonstration:
from pyspark.sql import Row
# Sample data
data1 = [Row(id=1, name='Alice'), Row(id=2, name='Bob'), Row(id=3, name='Cathy')]
data2 = [Row(id=1, age=34), Row(id=2, age=45), Row(id=4, age=23)]
df1 = spark.createDataFrame(data1)
df2 = spark.createDataFrame(data2)
df1.show()
df2.show()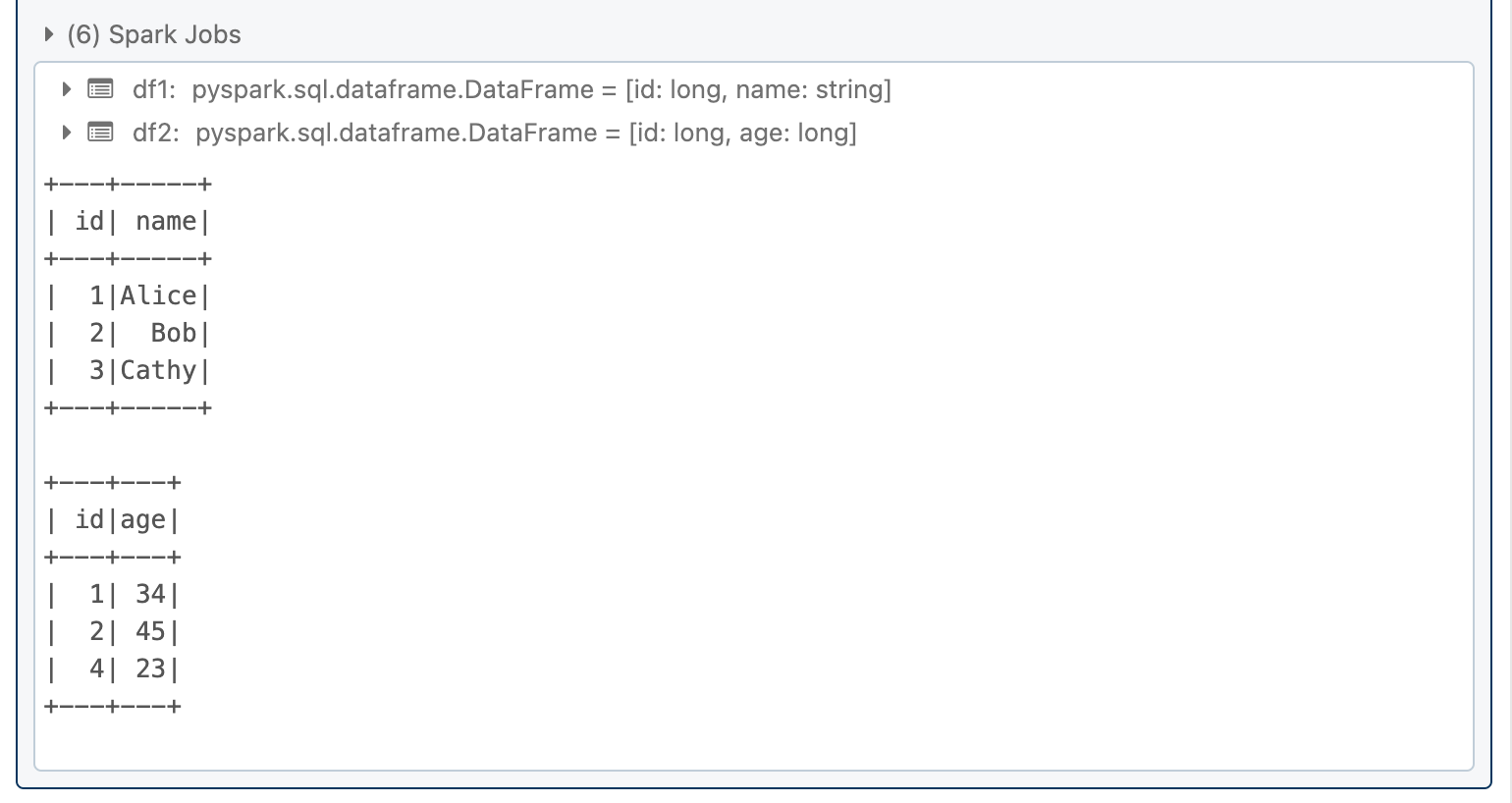
Inner Join
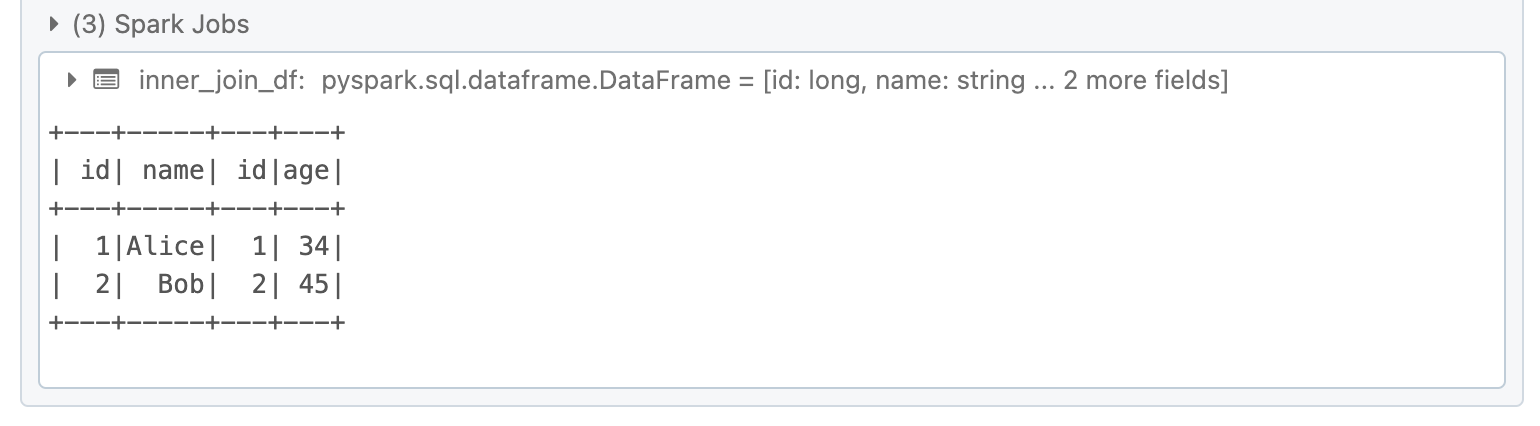
An inner join returns only the rows that have matching keys in both DataFrames.
inner_join_df = df1.join(df2, df1.id == df2.id, "inner")
inner_join_df.show()
Left Join
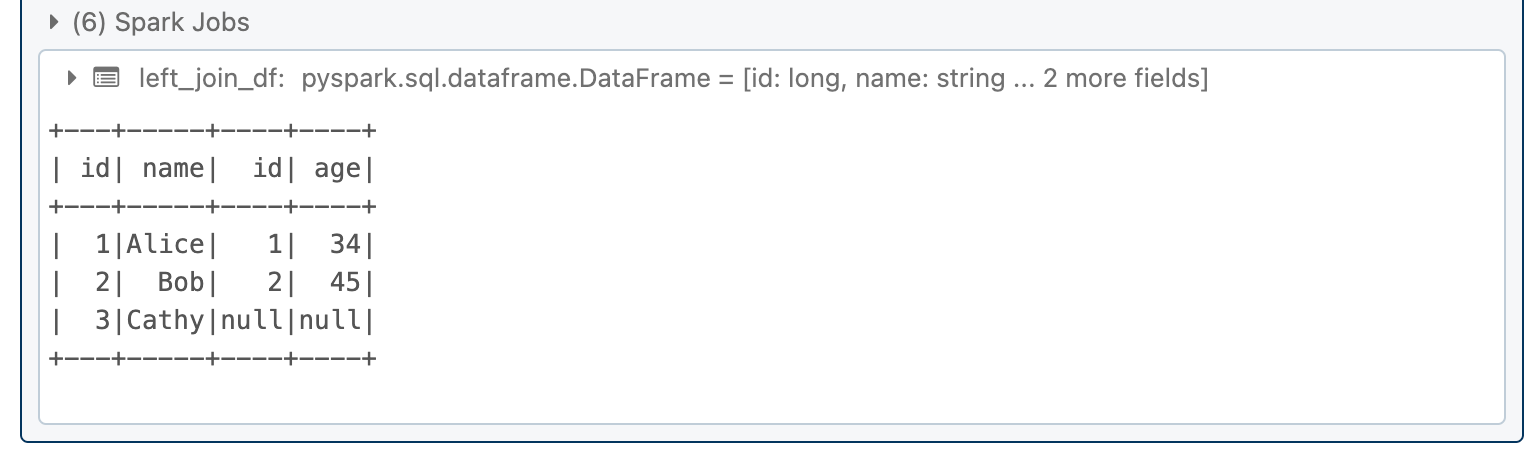
A left join returns all rows from the left DataFrame and matched rows from the right DataFrame.
left_join_df = df1.join(df2, df1.id == df2.id, "left")
left_join_df.show()
Right Join
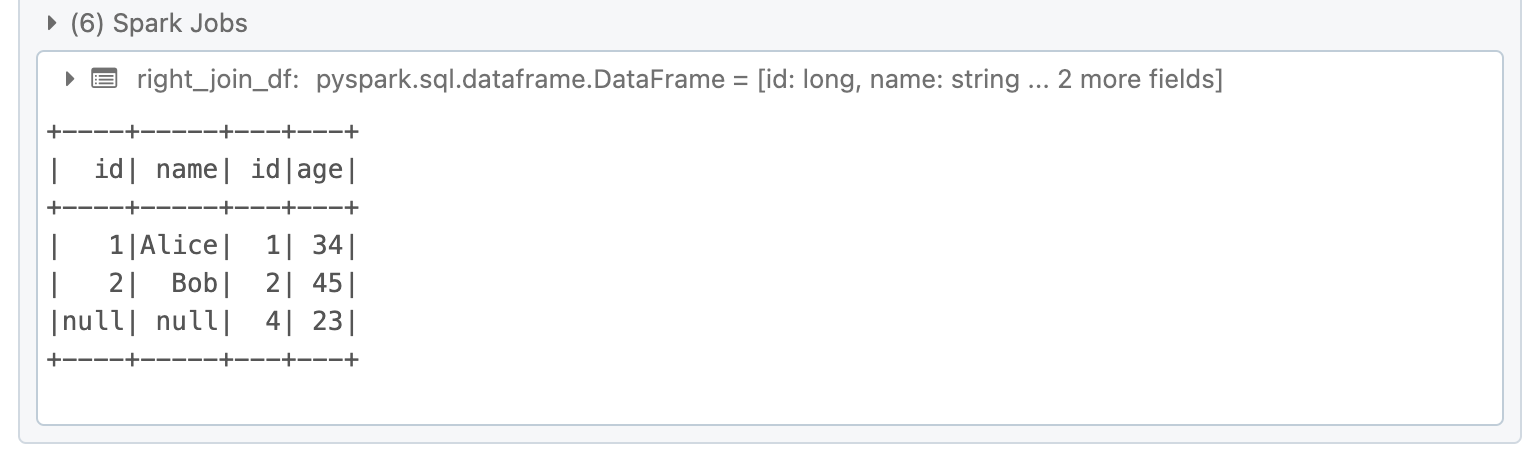
A right join returns all rows from the right DataFrame and matched rows from the left DataFrame.
right_join_df = df1.join(df2, df1.id == df2.id, "right")
right_join_df.show()
Full Outer Join
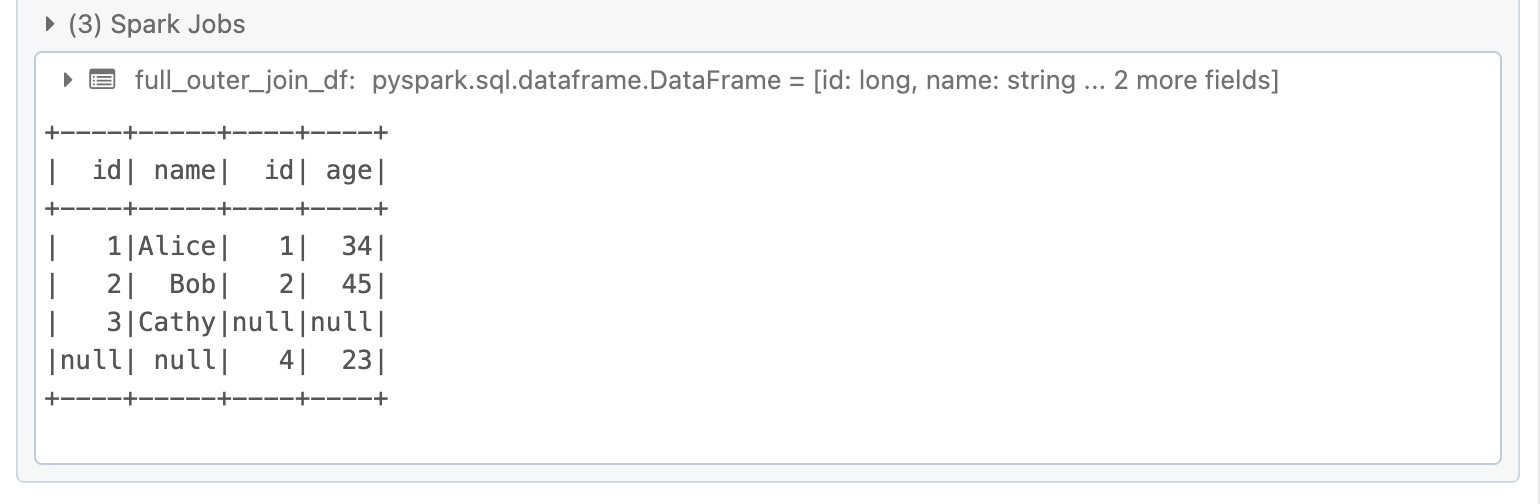
A full outer join returns all rows when there is a match in either the left or right DataFrame.
full_outer_join_df = df1.join(df2, df1.id == df2.id, "outer")
full_outer_join_df.show()
Cross Join
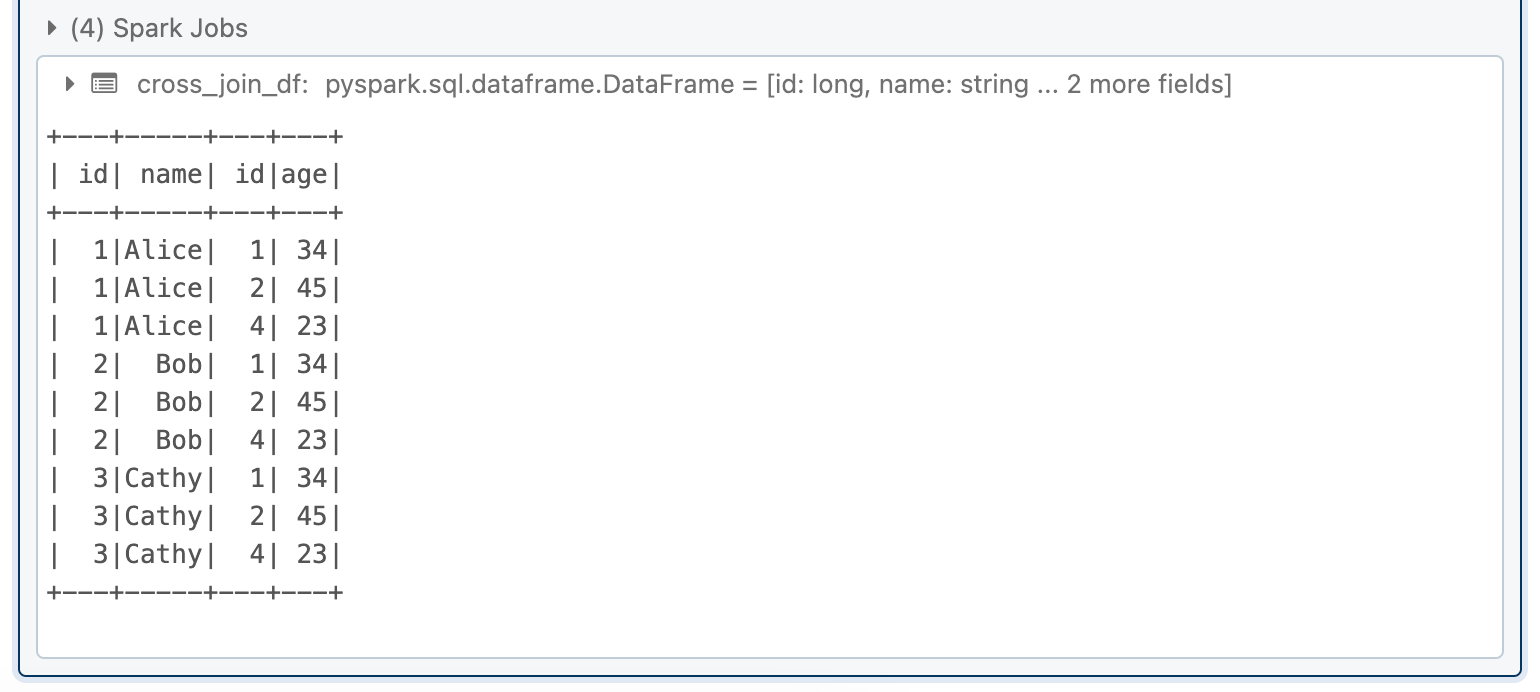
A cross-join returns the Cartesian product of the two DataFrames.
cross_join_df = df1.crossJoin(df2)
cross_join_df.show()
Semi Join
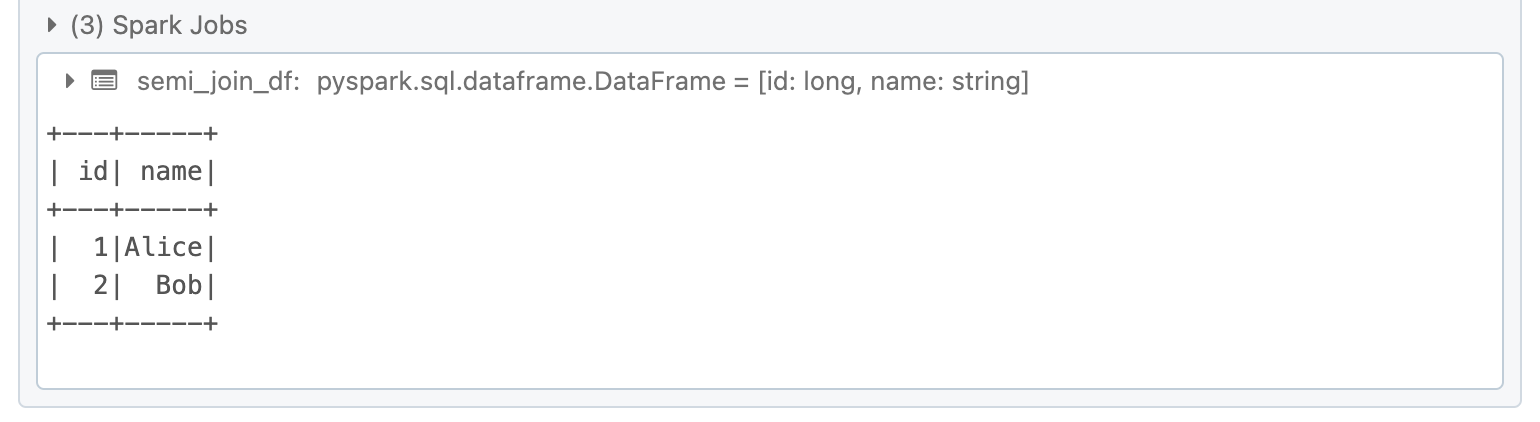
A semi-join returns only the rows from the left DataFrame that have matching rows in the right DataFrame.
semi_join_df = df1.join(df2, df1.id == df2.id, "leftsemi")
semi_join_df.show()
Anti Join
An anti-join returns only the rows from the left DataFrame that do not have matching rows in the right DataFrame.
anti_join_df = df1.join(df2, df1.id == df2.id, "leftanti")
anti_join_df.show()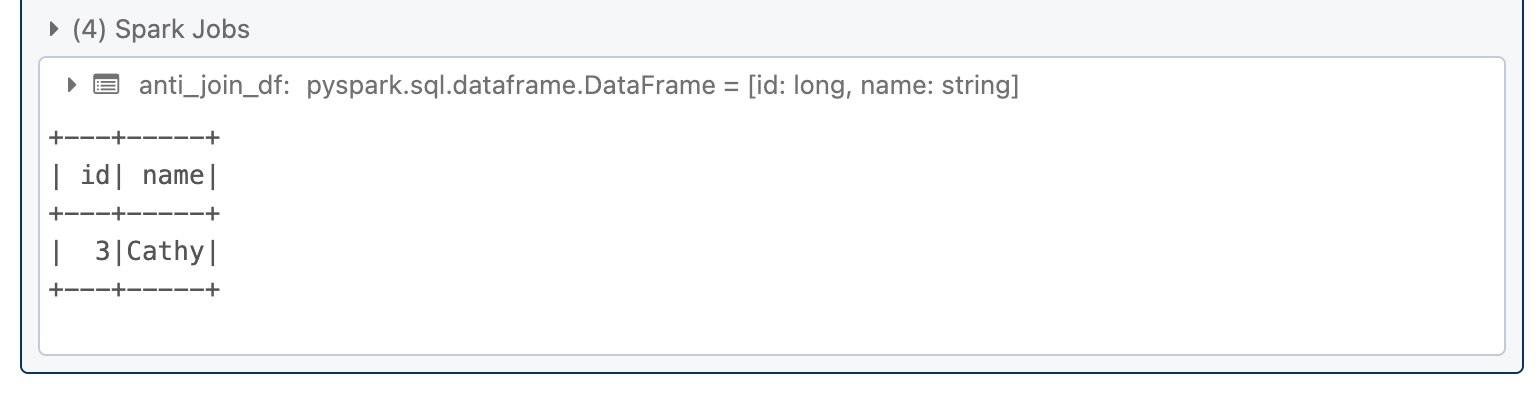
Conclusion
In this guide, we explored the various types of DataFrame joins available in Spark, each serving different data integration purposes. By understanding and implementing these joins, you can perform complex data transformations and analyses effectively. Try out the examples provided and experiment with your datasets to deepen your understanding of Spark DataFrame joins.
Additional Resources
Recommended books: "Learning Spark" by Holden Karau and "Spark: The Definitive Guide" by Bill Chambers.
Connect with me on LinkedIn